Trusted by the industry's largest disruptors.


Proteus
Artificial Intelligence in Maritime
AI is here, and so is the Maritime Industry's first patent pending Model Orchestration to identify gaps and employ data-driven AI solutions that save time, resources, and money.

pRoteus
born at greyWing
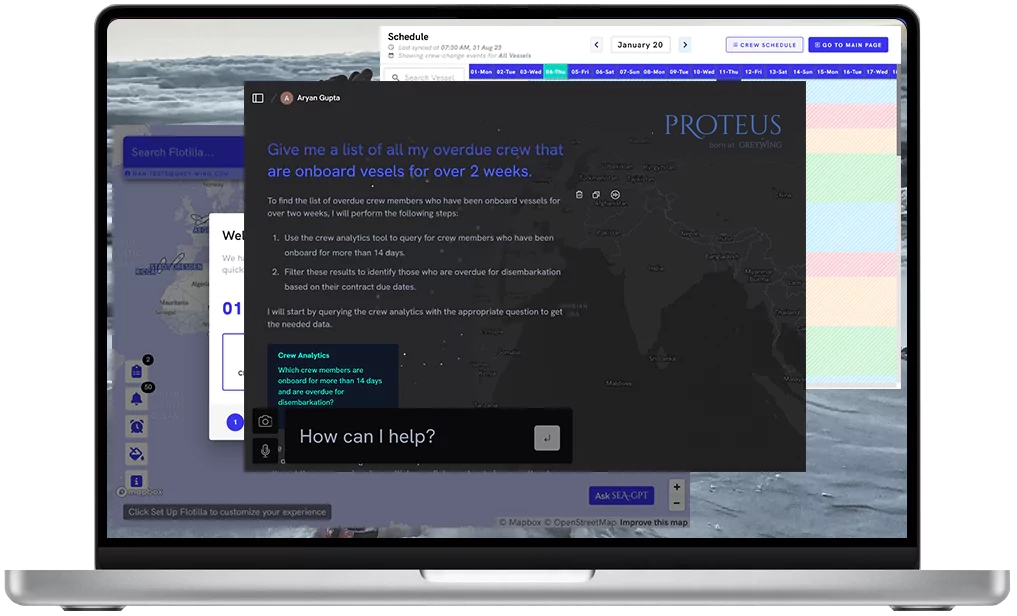
Proteus for Crewing
Data is convoluted and hard to retrieve when it comes to Crew Planning. Proteus plugs into your crewing software's data and fetches you insights within seconds. Go from summarizing overdue crew onboard vessels to finding last minute replacements within seconds.
Compare nationalities of onsigners and offsigners onboard vessel Going Merry using a line graph
To compare the nationalities of onsigners and offsigners onboard the vessel 'Going Merry', we will first retrieve the crew data for the vessel, focusing on the onsigners and offsigners. Once we have the data, we will create a line graph to visualize the comparison.
Proteus for Technical
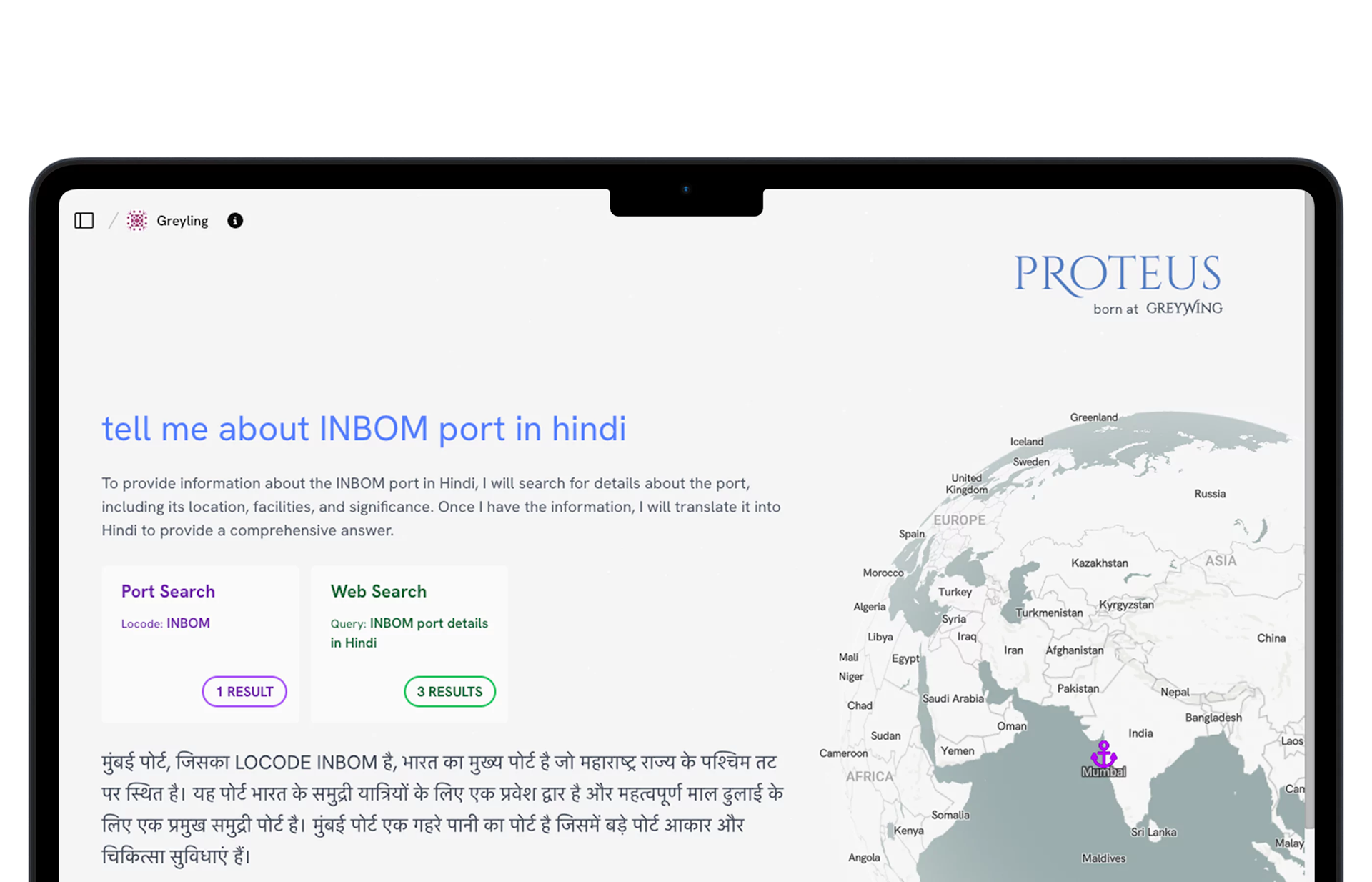
Ocean Oracle, is Greywing's Proteus applied to complex Manuals. Simply drag and drop any training manual or company-specific document and ask the engine any question. Sit back while Proteus digests, learns, and teaches the data to you.
Features
Multilingual Support
Speak to Proteus in over 40 languages. Enjoy voice-activated access to derive quick insights for your Crewing, Commercial, or Technical Team.
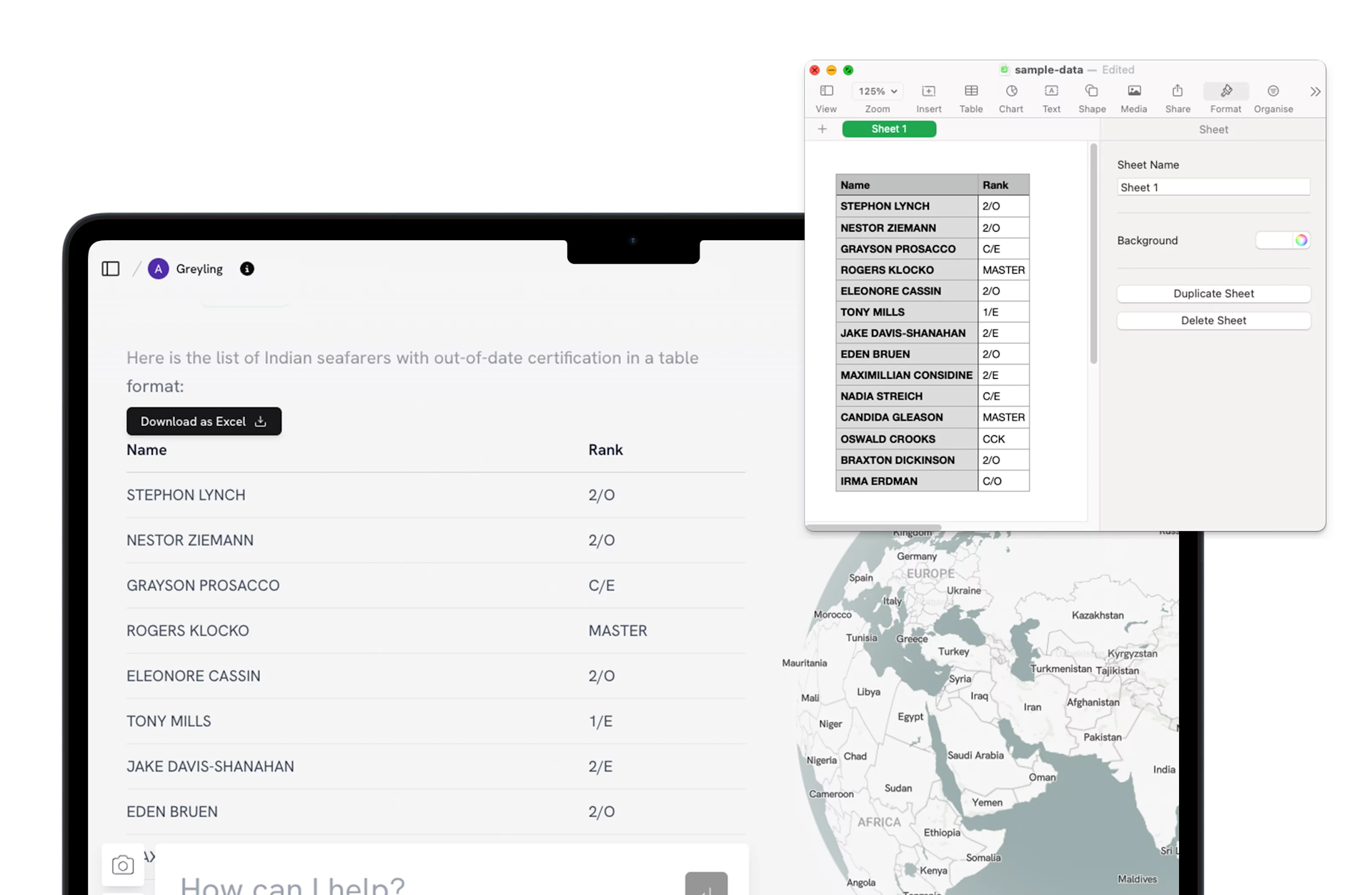
Export your insights
All insights from Proteus can be visualized in any format: from bar graphs to complex tables. Export your data in to Microsoft or Power BI in Seconds and always be presentation-ready.
Access all your software in one place
We pull as much data as you want to give us into one data lake so that data remains un-silo-ed and easy to retrieve across business units.
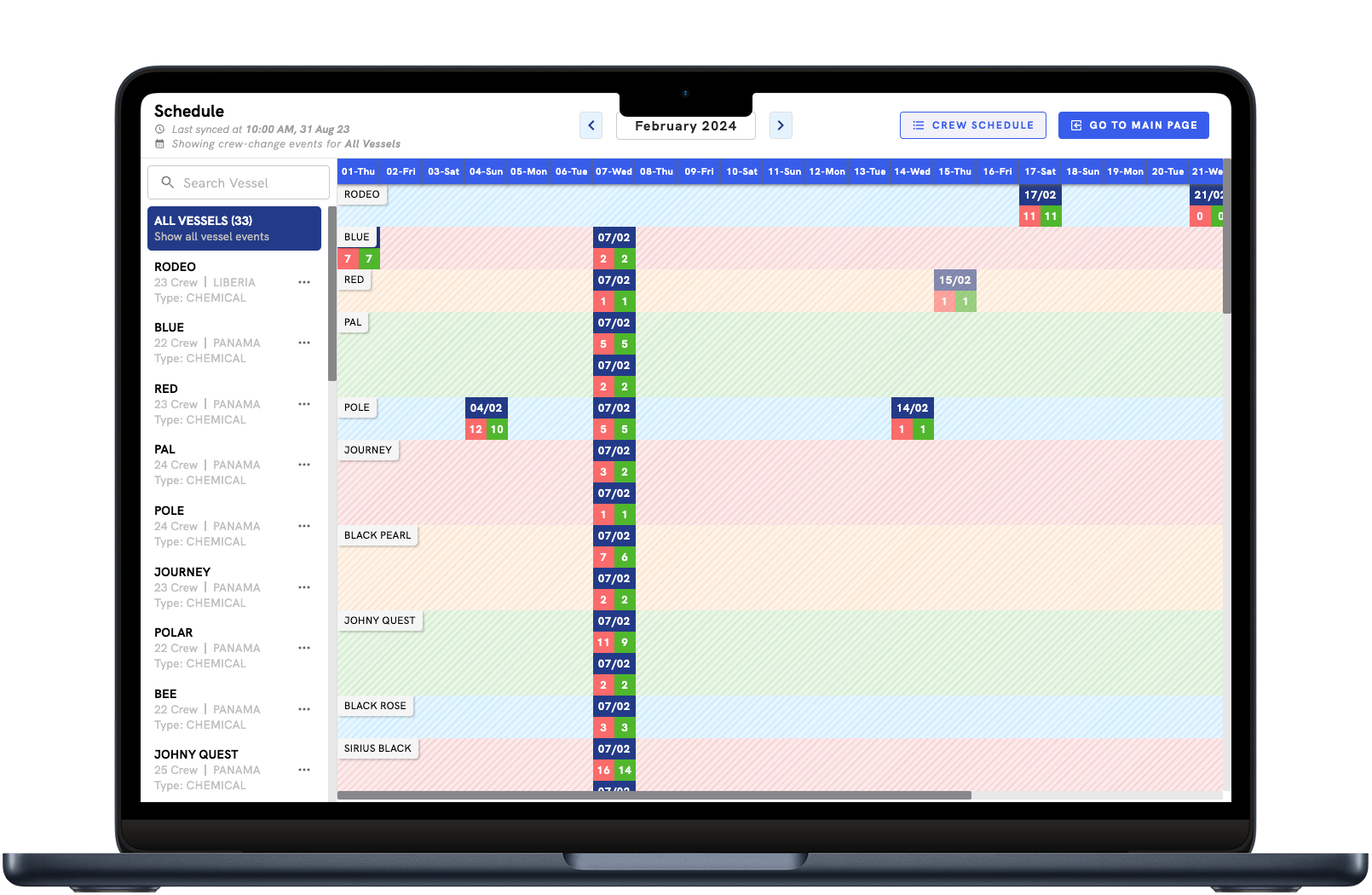
Crew Matrix Planning Engine
Automate Crew Planning 18 months into the future.
The Crew Matrix Planning Engine pulls data directly from your Crewing Software and looks at all of the requirements around Charterer, OCIMF, Oil Major, Flag States, and Customer Requirements to deliver automate crew matrix planning.
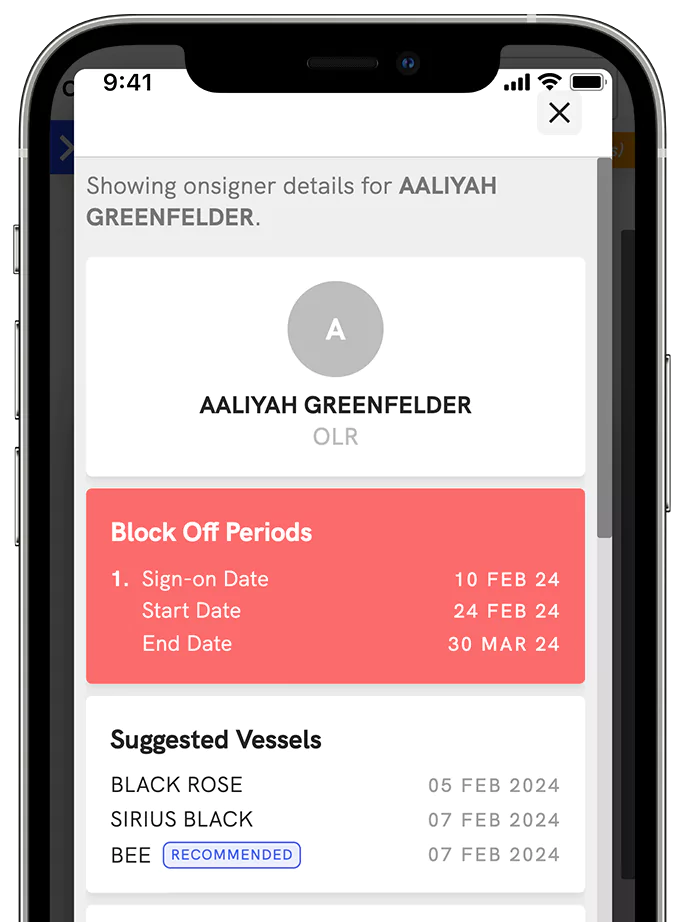
Say goodbye to last minute crew reshuffles.
Let our AI replan for you by pulling your readiness data and profile information into the engine. We show you multiple backup options if someone cannot join a vessel due to a last minute issue. We also ensure maximum cross utilisation of your seafarers across your offices and manning agency allocations.
Mitigate Domino Effects from Changed Crew Plans.
Pull seafarers from one crew plan into another without having to replan other crew pairings. Let AI replan all of your affected crew plans.
Compliant with Industry Standards
We do all this in line with your regulatory and compliance requirements: from charterer rules to OCIMF, Oil Majors, Flag States, and internal policies. Enjoy a completely customized tool that can plan a crew plan the way your team would.
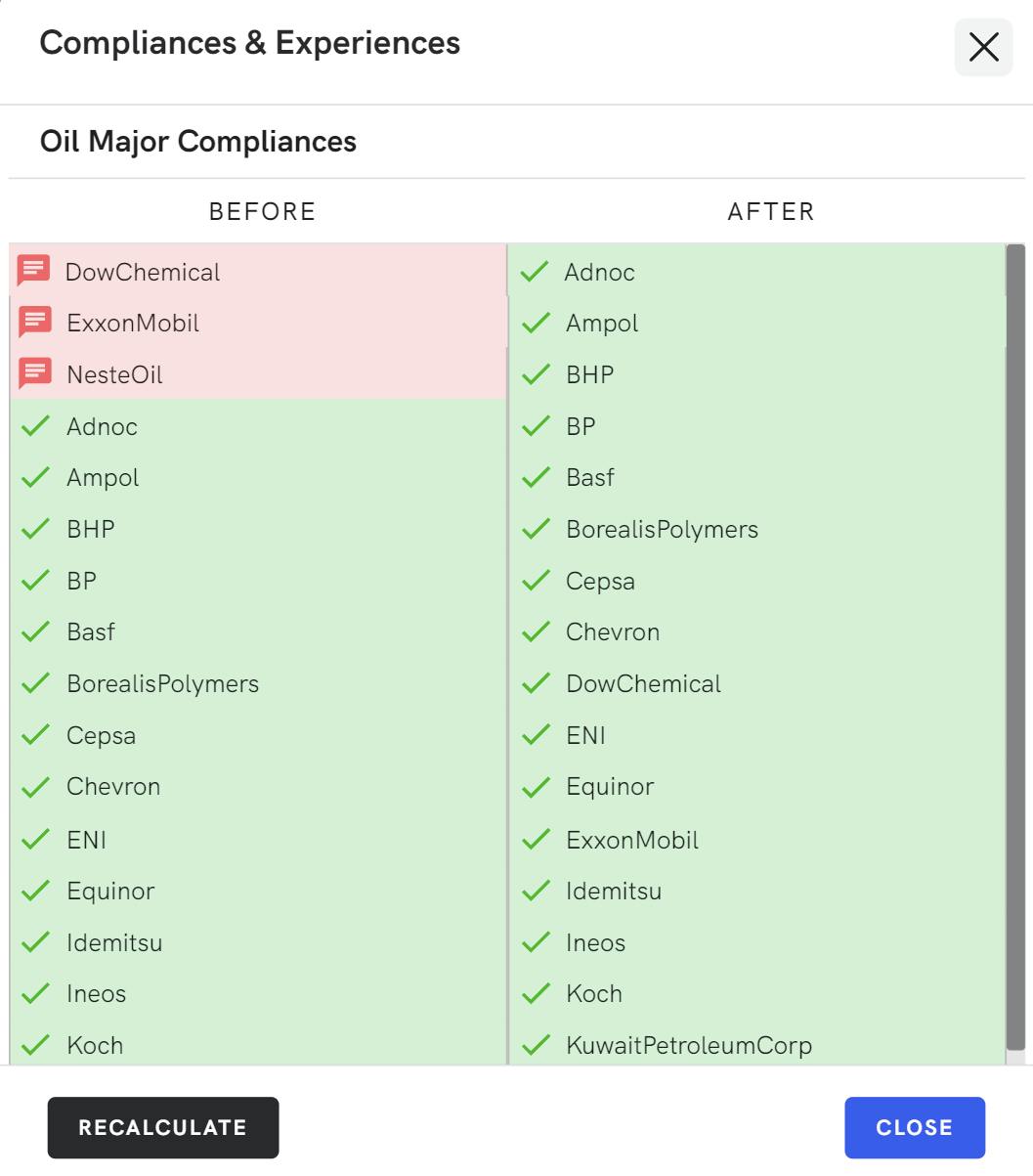
Seamless Integration
Lower costs, automate crew pairings, and give your Crewing Team more time. We integrate seamlessly with your crew management software and document information with no training.



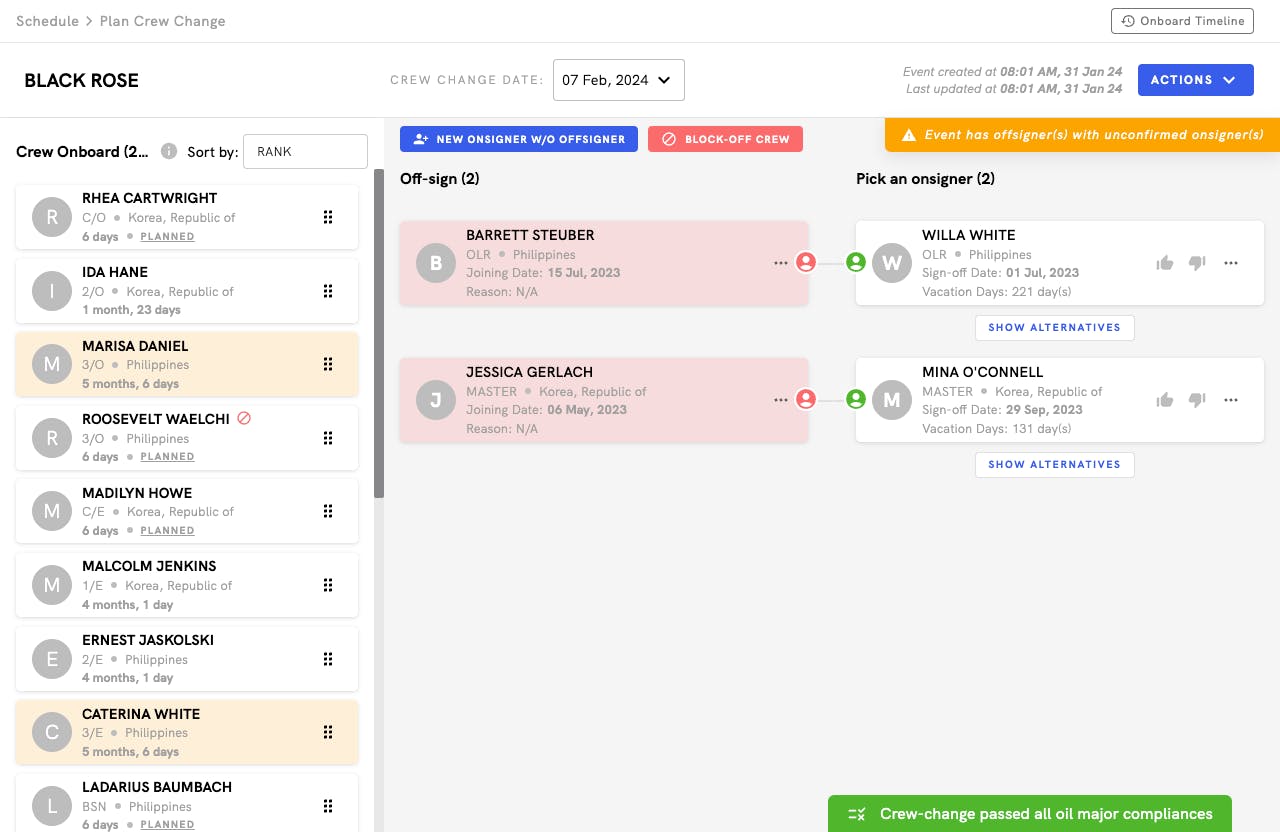
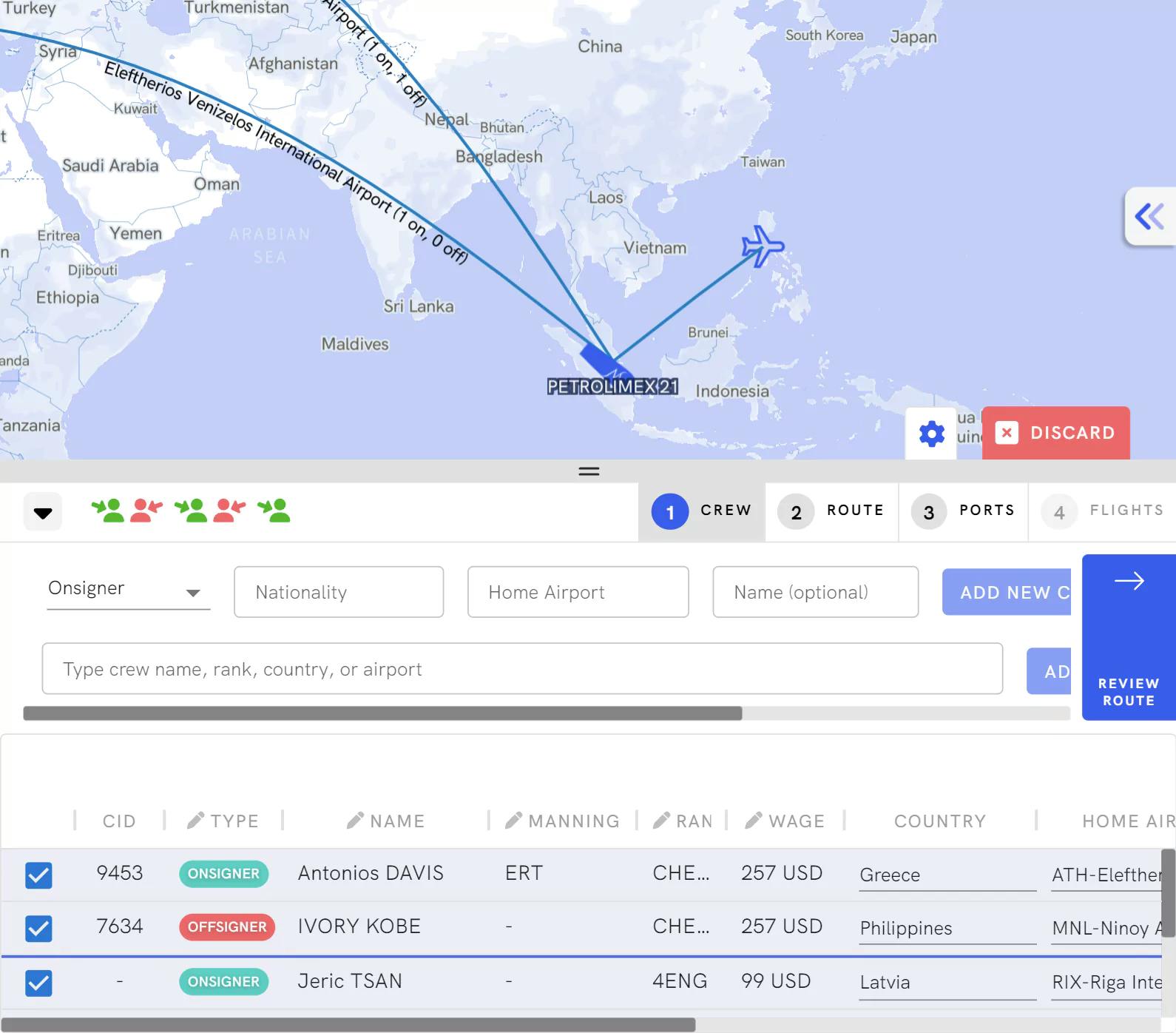
Crew Change
Planning Crew Changes has never been easier.
Manage the crew change process from the ship to shore and get your crew onto a vessel/ into their homes on time and under budget.
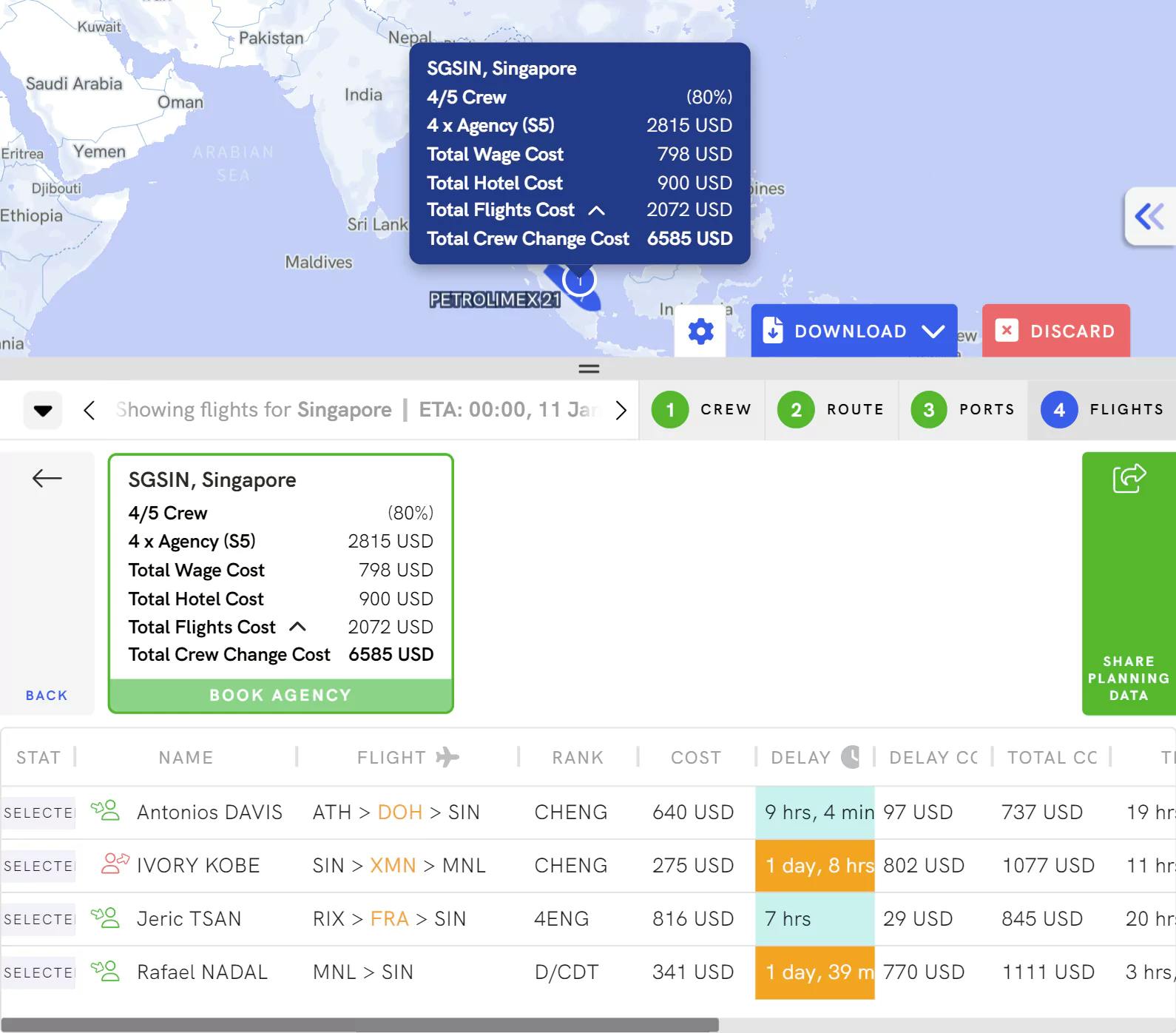
Minimize Costs
Optimise your port calls and port agencies based on an apples to apples comparison through immediately plugged pricing on Greywing.
Have eyes around the clock with Greywing and get your after-hours updates with our daily rollouts.
Updates (11)
- 4 minutes agoRICCA has changed STATUS from NOT UNDER COMMAND to UNDER WAY USING ENGINE.
- 8 hours agoMSC BASEL V has changed STATUS from MOORED to UNDER WAY USING ENGINE.
- 10 hours agoSTADT DRESDEN has changed NEXT PORT NAME from NEW YORK to NORFOLK.
- 18 hours agoSTADT DRESDEN has changed STATUS from UNDER WAY USING ENGINE to MOORED.
- 20 hours agoRICCA has changed NEXT PORT NAME from PRIMORSK to UST LUGA.
- 20 hours agoRICCA has changed STATUS from MOORED to NOT UNDER COMMAND.
- 7 hours agoPORT RESTRICTIONS for CONGO DEMOCRATIC REPUBLIC OF THE was updated by WILHELMSEN.
- 7 hours agoPORT RESTRICTIONS for HONG KONG was updated by WILHELMSEN.
- 7 hours agoPORT RESTRICTIONS for EGYPT was updated by WILHELMSEN.
- a day agoPORT RESTRICTIONS for CONGO DEMOCRATIC REPUBLIC OF THE was updated by WILHELMSEN.
- a day agoPORT RESTRICTIONS for HONG KONG was updated by WILHELMSEN.
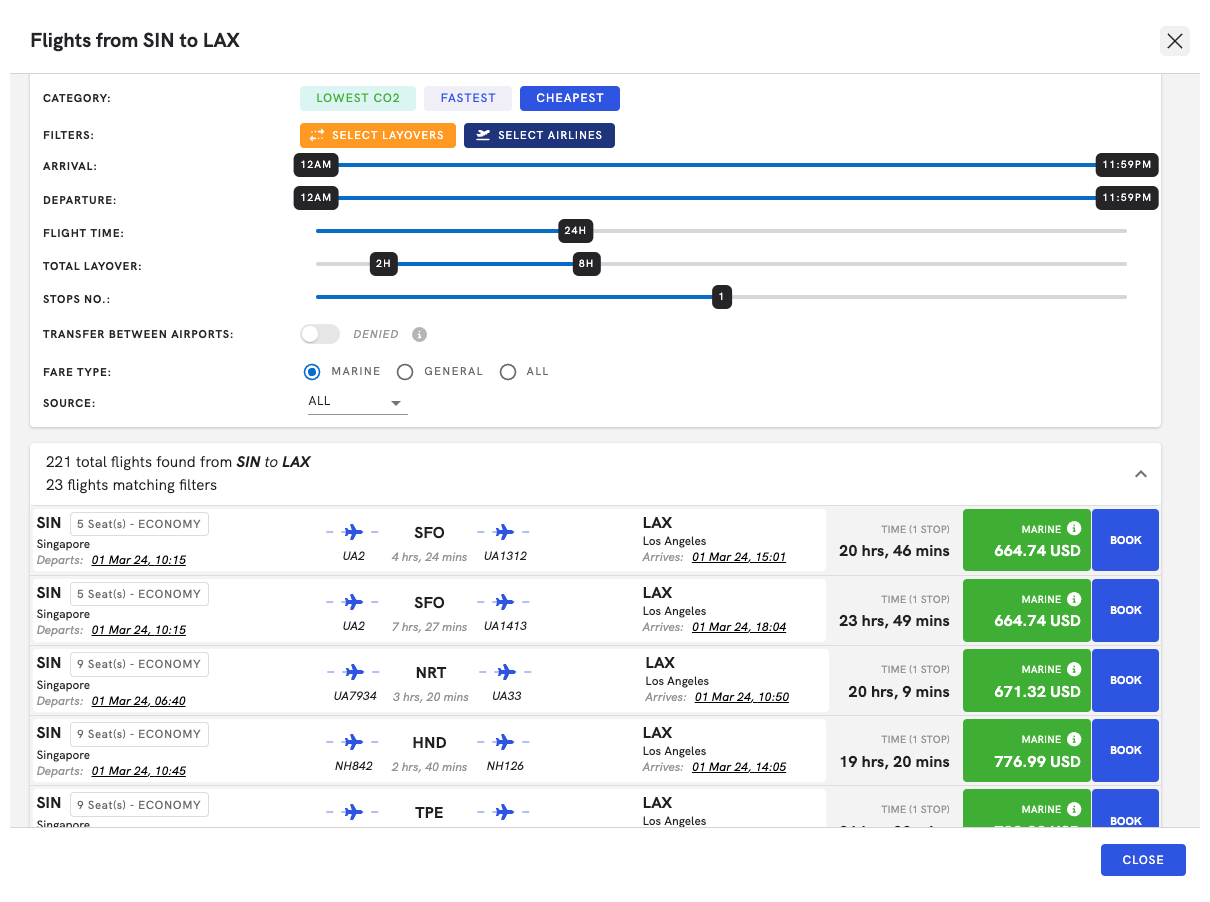
Book Flight at Lowest Prices
Select flights for crew straight from your travel agencies and hand off the process to an agent to complete the booking or to recommend better flights.
Communication made simpler
Collaborate over notes from other team members on a voyage, vessel, or crew member. Keep a one-stop shop globally and across stakeholders.
QuickFly
Access marine fares through our search engine.
We can integrate with any maritime travel companies that you work with, or you can request to work with any of our 8 onboarded travel agencies.
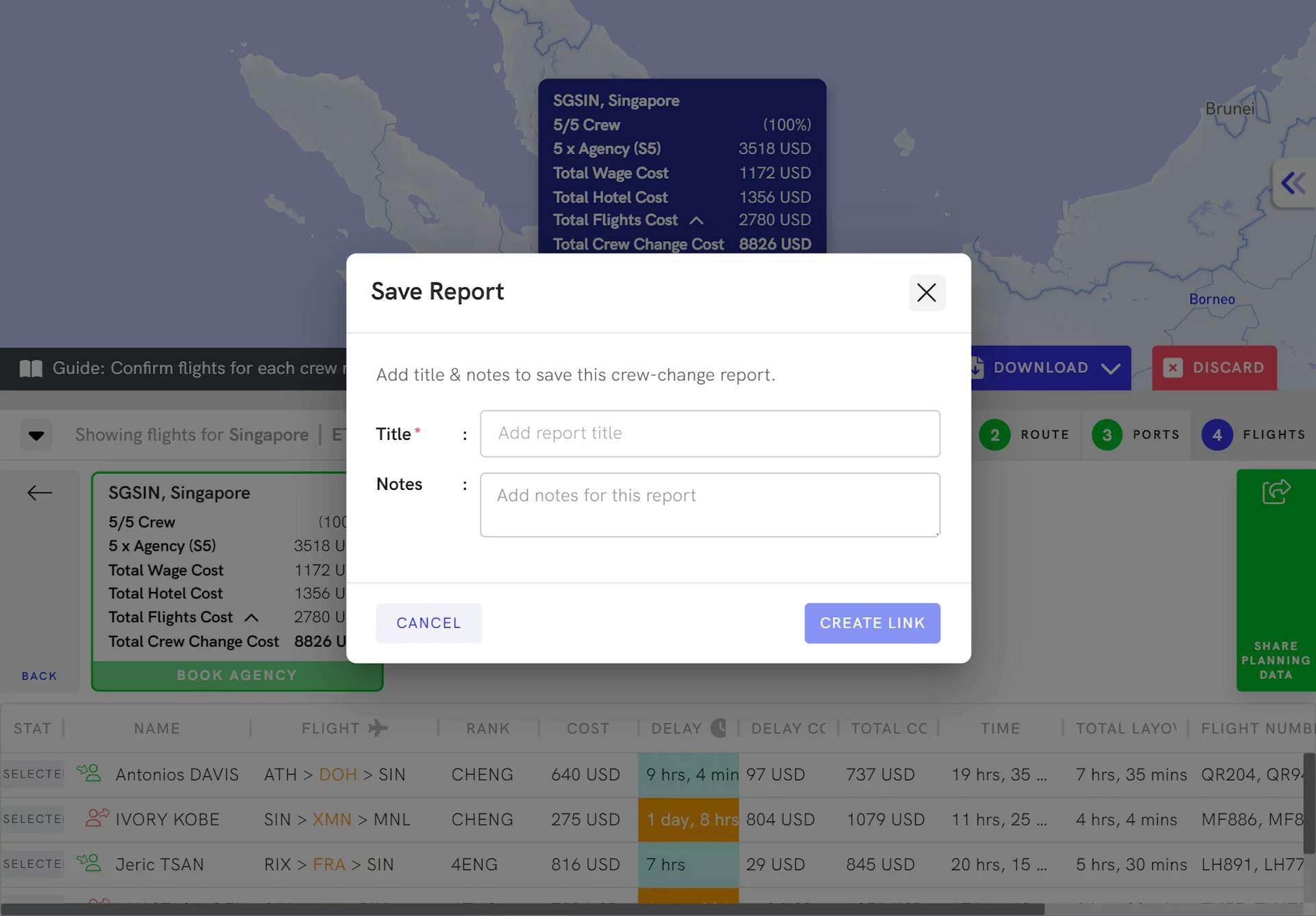
Generate Reports
Extract reports on complete crew change plans including tentative live pricing from your travel agents in order to estimate the total crew change cost. Share these reports with anyone in your organisation.
Automated Port Agency Outreach
Automate costly conversations.
Shipping operatives spend too much time on their vendors. We automate your communications with vendors, starting with port agents. We initiate the quotation request, have the back and forth around data required, and finally, hand off the conversation to your personnel when there is a decision point.
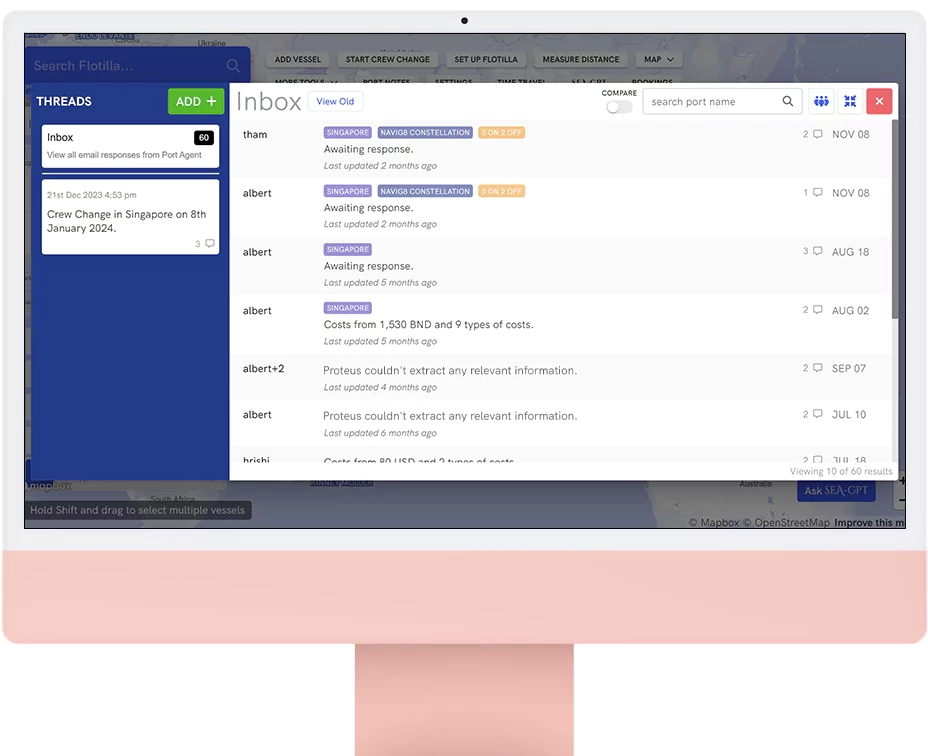
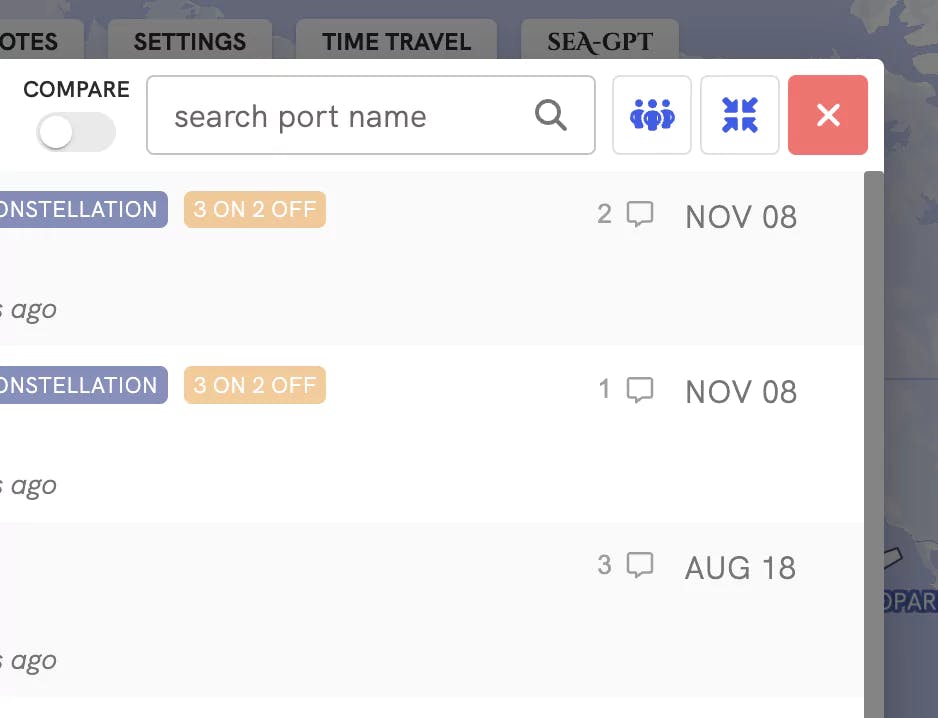
Shared Inbox to Rule them All.
Shipping also has too much duplication. View any of your teammate's conversations with a vendor and access old quotations received from a port agent so that you're minimizing your own work.
Others
Track Activity
Get an overview of all the committed activity on Greywing to ensure you have a comprehensive audit trail of your team's actions.
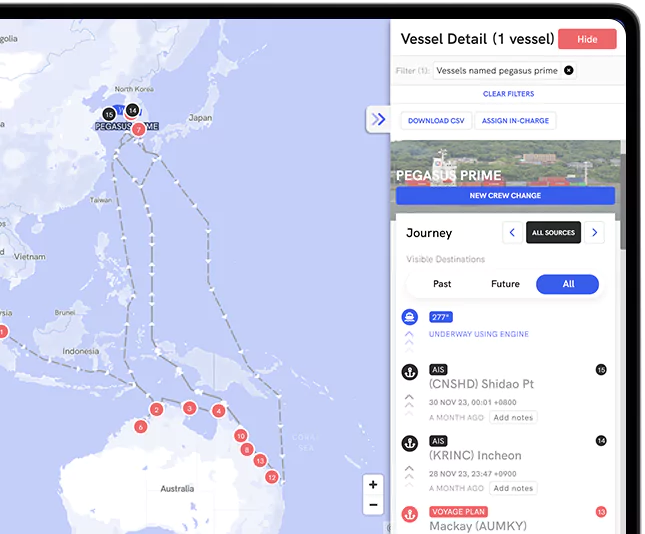
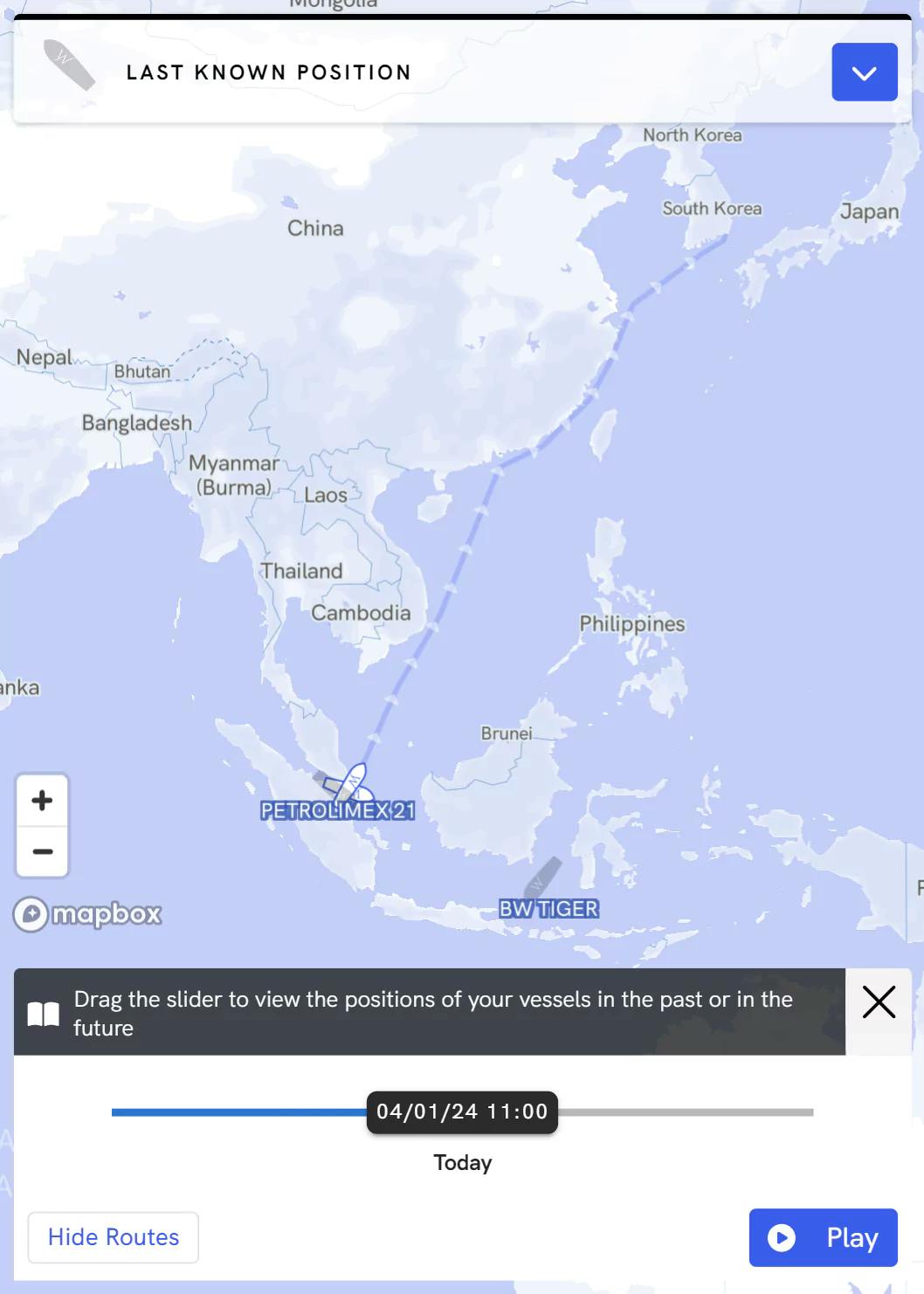
Real time Vessel Tracking
Always have situational awareness of where your vessel is on a map. Geo-locate your vessel instantly on our interactive map with live Satellite AIS or your voyage system.
Filters, Notifications, and Search
Find any feature with Flotilla Search Wizard and subscribe yourself to vessel, voyage, or cargo related notifications via email.
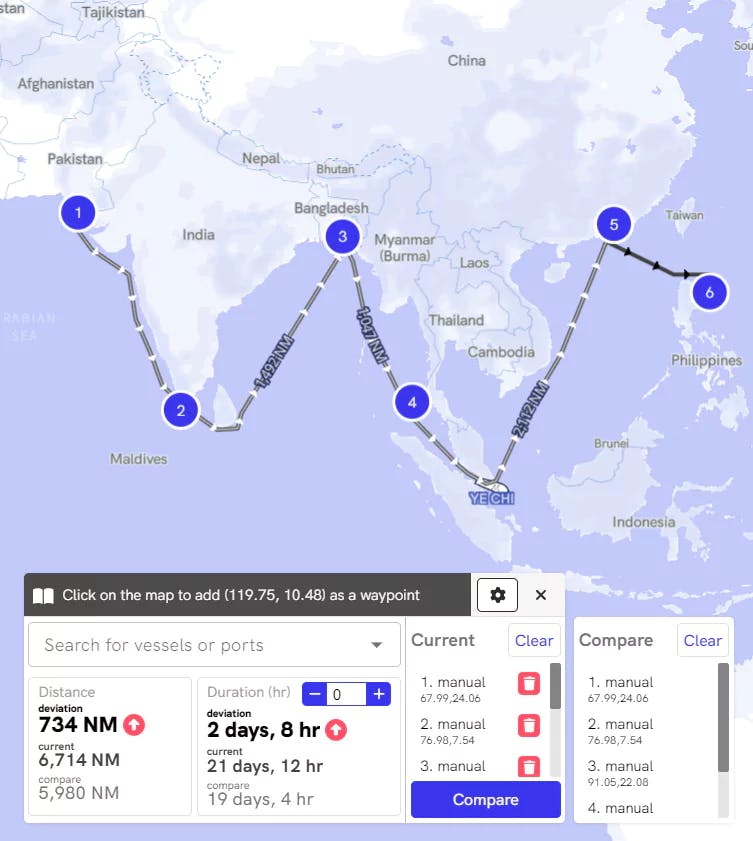
Ruler
Estimate the distance between any number of ports or a route and get an overview of your vessel's deviation in terms of time and fuel costs.
Privacy and Security
Built with your privacy in mind
Don't let software providers hold your data hostage. Greywing connects to any and all softwares and can push data within itself out to our clients.
- Certified:Our providers are transparent, run on cloud providers with SOC2, ISO certifications, and are only allowed access to data on user request.
- PII protected:Greywing can remove your personally identifiable information from data so that only approved providers can even see them,.
- Encrypted both in transport and at rest:All of your data sits exactly where you want it to, protected with multiple layers of security.
Set your permissions
Assign people in charge for certain activities and establish locked actions in order to mimic your real life workflows on Greywing.
